这篇论文相当经典,基本上后来的每篇文章都会将和这篇论文的结果作对比。但是这篇论文对我来说,有点生涩难懂,这是看的第二遍了。特来记录一下。
基本信息
- 年份:2016
- 期刊:NIPS
- 标签:Meta Learning、Attention、Memory
- 数据:Omniglot、Mini-ImageNet
创新点
- 模型方面,结合了注意力模块和记忆模块(输入为set),使得网络可以快速学习。其中注意力模块和度量学习和相似,所以也可以看成是度量学习(metric learning目前小样本学习的主流方法)和记忆模块(external memories以前小样本学习的主流方法)的结合
- 训练过程基于一个简单的机器学习原则:训练和测试是要在同样条件下进行的,“one-shot learning is much easier if you train the network to do one-shot learning”。提出在训练的时候不断地让网络只看每一类的少量样本,这将和测试的过程是一致的
- 模型学习了一个网络,它将带标签支撑集和一个无标签的查询集映射到它的标签上,从而避免了为了适应新的类类型而进行微调的需要
- 完成了一个端到端的完全可微分的近邻方法
- 提出了Mini-ImageNet基准数据集
创新点来源
One-shot Learning,每一类中只有一个已知类标的样本。数据增强和正则化技术可以缓解在少量数据集上的过拟合,但是不能解决这个问题。对于参数化的模型,需要经过训练,训练样本需要由模型慢慢的学习到参数中,所以会导致学习慢,需要很多次的权重迭代。相反,对于无参数化的模型,可以快速适应新样本,同时没有遭受灾难性的遗忘,但是这种方法的性能太依赖于参数的度量方式。本文主要是将参数化的模型和无数化的模型进行结合,即快速获取新示例(非参数化的模型),同时从常见示例中提供出色的概括(参数化模型)。也就是训练一个完全端到端的近邻分类器。
关于参数化模型和非参数化模型的对比,我觉得可以这样理解:给定一个训练集,在参数化的方法中,需要一步步的迭代学习其中的特征,学习很慢;而在非参数化的模型中,例如KNN,训练集都存储下来了,来一个测试样本需要跟训练集中所有样本比较,可以快速适应新样本,同时没有灾难性的遗忘。
主要内容
模型结构
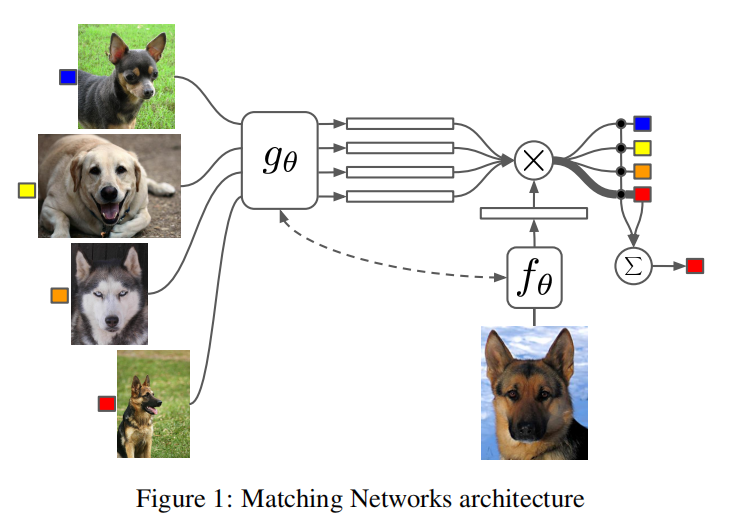
神经元注意力机制通常完全可微分,定义为访问存储有用信息的记忆力矩阵来解决手头的任务。external memories有很多种。在机器翻译,声音识别以及问答中这些结构模型为$P(B\mid A)$,其中$A$和(或)$B$可以为序列,代表external memories。而对我们来说external memories是集合,如上图所示,网络的输入是多个图片组成的set。
本文的贡献在于将One-Shot Learning问题映射到集合到集合的框架,在训练过程中,在不改变模型的情况下,可以产生查询集的类别。更精确地说,我们希望映射包含$k$个pair的支撑集$S$到分类器$C_s(\hat x)$。将查询样本$\hat x$输入到分类器中,产生$\hat y$的分布。我们定义映射$S \rightarrow C_s(\hat x)$为$P(\hat y \mid \hat x, S)$,其中$P$由一个神经网络参数化。更一般的,当给定查询样本$\hat x$和支撑集$S$的时候,预测输出为$argmax_yP(y|\hat x, S)$。
最重要的是下面这个公式的理解,给定包含$k$个pair的支撑集$S$,其每一个pair用$(x_i, y_i)$表示,给定查询样本$\hat x$,其属于各个类别的概率可以用下式计算:
其中,$f$和$g$可以是合适的神经网络,分别对$\hat x$和$x_i$进行嵌入;$c$表示余弦距离;$a$为注意力机制。从公式可以看出$\hat y$为支撑集类标$y_i$的线性组合。这有几种理解方法:
- 当$a(\hat x,x_i)$为标量,表示查询样本$\hat x$和支撑样本$x_i$之间的相似度;而$y_i$为向量,表示支撑样本$x_i$对应的one-hot类标。将$a(\hat x,x_i)$和$y_i$相乘得到一个向量,只有在$x_i$所属的类别有值,且值等于查询样本$\hat x$和支撑样本$x_i$之间的相似度。将$k$个这样的向量按元素相加,得到一个新向量,该向量中的元素表示$\hat x$属于各个类别的概率,且相当于经过了softmax函数。这类似于kernel density estimator(KDE)算法。
- 将$\hat x$和$x_i$之间距离最远的$b$个$a(\hat x,x_i)$置为0或者根据合适的常量将其中的$b$个置为0,这就相当于$k-b$近邻。
- 将$\hat x$和$x_i$之间距离最近的$a(\hat x,x_i)$置为1,$y_i$为和$x_i$一一对应的memory,就像一个哈希表。在这种情况下,我们可以理解为一种特定的associative memory,给定一个输入,找到支撑集中的相应示例,检索其标签。然而和一般的attentional memory machanisms不同,公式$({1})$具有本质的无参数性(non-parametric):随着支撑集的增加,所使用的memory也增加。
non-parametric:这里解释一下什么叫做non-parametric。首先,任何一个模型(Model)的建立都有其基础或假设(Assumptions)。而参数模型(parametric models)和非参数(Nonparametric models)亦不例外:二者最主要的区别是关于数据分布的假设——参数模型对数据分布(distribution,density)有假设,而非参数模型对数据分布假设自由(distribution-free),所以模型结构不是先验指定的,而是根据数据确定的。Nonparametric models也被称为distribution free.所以,回顾二者的名字“参数”,即指数据分布的参数。
注意力机制
注意力机制最简单的形式为余弦距离经过softmax函数,这和一般的注意力机制以及核函数有着紧密的联系。
关于这两个方式和公式$({1})$联合在一起怎么解释,请看上面的理解方式一。
注意这虽然和度量学习也相关,但是由公式$({1})$定义的分类器是不同的,我们使用了整个支撑集$S$而不是成对的比较,这更适用于One-Shot Learning(TODO)。 对于给定的支撑集$S$和查询集$\hat x$,这是足够的将$\hat x$指派给$(x’,y’) \in S$,所以$y’=y$,和其他的支撑集不重合(TODO)。
注意在本文中所有的带$’$的符号表示在测试集中的数据,以区别与训练过程中的数据。
Full Context Embeddings
$x_i$的嵌入函数应该同时由$x_i$和支撑集$S$决定。support set是每次随机选取的,嵌入函数同时考虑support set和$x_i$可以消除随机选择造成的差异性(因为要比较$\hat x$和$x_i$的相似性,让$x_i$的嵌入和整个$S$有关可以减少随机挑选带来的误差)。这样嵌入函数就从$g(x_i)$变成了$g(x_i,S)$。类似机器翻译中word和context的关系,$S$可以看做是$x_i$的context。
除此之外,现在对$\hat x$的嵌入和对$x_i$的嵌入没有任何关联。但是support set是每次随机选取的,这样可能导致对于$\hat x$的预测出现偏差。为了消除这种随机选择造成的差异性,可以让对$x_i$的嵌入与$\hat x$有关。也就是说支撑集样本应该可以用来修改查询集的embedding模型$f$。嵌入函数就从$f(\hat x)$改为了$f(\hat x, S)$。
这两个问题可以分别通过下面两个方法解决,文中称这两种方法为FCE (fully-conditional embedding)。
1)基于 attention-LSTM 来对查询样本 embedding $f$ ,使得每个 Query 样本的 embedding 是支撑集 embedding 的函数。公式如下:
其中,$f’(x)$是特征(CNN嵌入层的输出,如VGG、Inception),作为LSTM的输入(在每一个time step为常量)。$K$为LSTM层的timesteps,等于support set的图片个数。$g(S)$表示support set中每一个样本$x_i$经过嵌入函数$g$。
经过$k$个steps后,状态如下:
对于$\operatorname{LSTM}(x,h,c)$,$x$为输入,$h$为输出(cell after the output gate),$c$为cell。$a$就是所谓的 “content” based attention。公式$({8})$中的softmax对$g(x_i)$进行标准化。从$g(S)$出来的read-out $r_{k-1}$和$h_{k-1}$相连。我们做$K$步的“reads”,$\operatorname{attLSTM}(f’(\hat x),g(x),K)=h_K$,其中$h_K$正如公式$({6})$所描述的那样。
在公式$({7})$中可能作者有个笔误:$r$的下标应该是$k$而不是$k-1$。
2)基于双向 LSTM 学习支撑集的 embedding $g$,使得每个支撑样本的 embedding 是其它训练样本的函数;更为精确地,让$g’(x)$为神经网络 (和上面的$f’$相似,例如一个VGG或者Inception模型)。然后我们定义$g\left(x_{i}, S\right)=\stackrel \rightarrow{h}_i+ \stackrel \leftarrow {h}_i + g^{\prime} \left(x_{i} \right)$
其中,对于$\operatorname{LSTM}(x,h,c)$,$x$为输入,$h$为输出(cell after the output gate),$c$为cell。注意$\stackrel \leftarrow {h}$ 从$i=|S|$开始。和公式$({6})$一样,我们在输入和输出添加一个skip connection。
注意,原文没有提及如何将无序的支撑集样本排序,但参考作者的另一篇文章文章:Order Matters: Sequence to Sequence for Sets。发现,这里将原本无序的支撑集样本集进行了排序。
有人可能会疑惑为什么要用LSTM,像LSTM、RNN这种模型都要记住一些东西,可是这些样本的类别又不同,所以是想要记住什么?网上有一个大佬的理解是将各个类别的样本作为序列输入到LSTM中,是为了模型纵观所有的样本去自动选择合适的特征去度量,例如如果我们的目标是识别人脸,那么就需要构建一个距离函数去强化合适的特征(如发色,脸型等);而如果我们的目标是识别姿势,那么就需要构建一个捕获姿势相似度的距离函数,这里需要参考一下度量学习(Metric Learning)。
训练策略
训练策略要保证训练和测试是要在同样条件下进行的。我们定义任务$T$为在可能的标签集$L$上的分布,考虑$T$为从所有的类中均匀采样到几个不同的类别(例如5),每个类别有几个样本(例如最多5个)。在这种情况下,从任务$T$中采样一个类标集合$L$,将有5到25个样本。
为了组成“episode”去计算梯度并更新我们的模型,我们首先从$T$中采样得到$L$(例如$L$可以为类别集合{cats,dogs})。我们使用$L$取采样得到支撑集$S$和一个查询集 $B$($S$和$B$都是cats和dogs的有类标样本)。Matching Nets的训练目标为:
从公式看出,这是元学习的一种形式,因为模型要学习如何从给定的支撑集中最小化在查询集上的loss。最重要的是,我们的模型不需要在新的类别上进行fine tuning,得益于它的无参数特性(因为模型并没有假设数据的分布,只取决于当前task的数据分布)。
缺点
- 该模型有一个缺点,当测试任务分布$T’$和训练所用的任务分布$T$相差很大的话,这个模型就不会work。
- 支撑集$S$增大时,计算梯度的代价也增大。
- 实现Full Context Embeddings的方式过于复杂。
思考
- 在
Full Context Embeddings小节中,能不能把一个task内的嵌入向量$g(x_i)$标准化,以此来实现$x_i$的嵌入函数应该同时由$x_i$和$S$决定。
疑惑
- 为什么嵌入函数$g$和$f$要使用不同的形式。为什么不能使用同一个嵌入函数。
参考
Matching Networks for One Shot Learning论文分析
论文阅读(35)Matching Networks for One Shot Learning
小样本学习(Few-shot Learning)综述
论文笔记:Matching Networks for One Shot Learning
Matching Networks for One Shot Learning
【One Shot】《Matching Networks for One Shot Learning》
Matching Networks for One-Shot Learning
核密度估计(kernel density estimation)
Category:Nonparametric statistics
能不能用简明的语言解释什么是非参数(nonparametric)模型?

